C语言是目前世界上流行、使用最广泛的程序设计语言。C语言对操作系统和系统使用程序以及需要对硬件进行操作的场合,用C语言明显优于其它语言,许多大型应用软件都是用C语言编写的。C语言具有绘图能力强,可移植性,并具备很强的数据处理能力,因此适于编写系统软件,三维,二维图形和动画它是数值计算的语言。
语言中的“结构体”其实就相当于其他语言中的“记录”,结构体的定义方法如下:
例如:
Struct student
{ int num;
char name[20];
char sex;
int age;
float score;
char addr[30];
};(注意的分号不能省略)。
其中行的“student”是该结构体的名称,花括号里面的内容是结构体的成员名,这是声明结构体的一般形式。也可以在声明结构体的同时对它进行初始化,例如:
struct stu
{
int num;
char *name;
char sex;
float score;
}pupil[5]={
{101,"Tom",'M',45.8},
{102,"Mike",'M',62.5},
{103,"Chris",'F',92.5},
{104,"Rose",'F',87.6},
{105,"Nate",'M',58.8}
};
该代码中的“pupil[5]”称为结构体数组,它属于结构体变量,在定义该变量的同时对它进行了初始化操作。我们也可以先声明结构体,然后再对它进行初始化操作。
例如:
#include <stdio.h>
int main()
{
struct student
{
char name[8];
int age;
char sex[4];
char depart[20];
float grade1,grade2,grade3;
}a;
float wage;
char c='Y';
if(c=='Y'||c=='y')
{
printf("\nName:");
scanf("%s", a.name);
printf("Age:");
scanf("%d", &a.age);
printf("Sex:");
scanf("%s", a.sex);
printf("Dept:");
scanf("%s", a.depart);
printf("Grade1:");
scanf("%f", &a.grade1);
printf("Grade2:");
scanf("%f", &a.grade2);
printf("Grade3:");
scanf("%f", &a.grade3);
wage=a.grade1+a.grade2+a.grade3;
printf("The sum of wage is %6.2f\n", wage);
}
return 0;
}
该程序中定义了一个名为“student”的结构体,变量名为“a”,然后再后面“if”包含的符合语句中对该结构体进行初始化。在此,我们可以看出,对结构体的初始化,只能对它里面的每个成员分别初始化。
#include <stdio.h>
struct stu
{
int num;
char *name;
char sex;
float score;
}pupil[5]={
{101,"Tom",'M',45.8},
{102,"Mike",'M',62.5},
{103,"Chris",'F',92.5},
{104,"Rose",'F',87.6},
{105,"Nate",'M',58.8}
};
void avg(struct stu *ps)
{
int c=0,i;
float ave,s=0;
for(i=0;i<5;i++,ps++)
{
s+=ps->score;
if(ps->score<60) c+=1;
}
printf("s=%.3f\n",s);
ave=s/5;
printf("average=%.3f\ncount=%d\n",ave,c);
}
int main()
{
struct stu *ps;
ps=pupil;
avg(ps);
return 0;
}
此程序是关于结构体指针变量作函数参数,这样可以提高程序的运行效率,程序中我们定义了一个“stu”的结构体,变量名为“pupil[5]”,并对其进行了初始化,在主函数中定义了一个该结构体的指针ps,将pupil赋值给ps,当函数avg()调用该结构体时,用指针ps来传递pupil的地址,从而,提高了该程序的效率。
结构体与指针的结合使用,可以有效的解决现实生活中的很多问题,因此C语言中的指针和结构体应该能够熟练的掌握。
语言的特点是:功能强、使用方便灵活。C编译的程序对语法检查并不象其它语言那么严格,这就给编程人员留下“灵活的余地”,但还是由于这个灵活给程序的调试带来了许多不便,尤其对初学C语言的人来说,经常会出一些连自己都不知道错在哪里的错误。看着有错的程序,不知该如何改起,本人通过对C的学习,积累了一些C编程时常犯的错误,写给各位学员以供参考。
1.书写标识符时,忽略了大小写字母的区别。
main()
{
int a=5;
printf("%d",A);
}
编译程序把a和A认为是两个不同的变量名,而显示出错信息。C认为大写字母和小写字母是两个不同的字符。习惯上,符号常量名用大写,变量名用小写表示,以增加可读性。
2.忽略了变量的类型,进行了不合法的运算。
main()
{
float a,b;
printf("%d",a%b);
}
%是求余运算,得到a/b的整余数。整型变量a和b可以进行求余运算,而实型变量则不允许进行“求余”运算。
3.将字符常量与字符串常量混淆。
char c;
c="a";
在这里就混淆了字符常量与字符串常量,字符常量是由一对单引号括起来的单个字符,字符串常量是一对双引号括起来的字符序列。C规定以“\”作字符串结束标志,它是由系统自动加上的,所以字符串“a”实际上包含两个字符:‘a'和‘\',而把它赋给一个字符变量是不行的。
4.忽略了“=”与“==”的区别。
在许多语言中,用“=”符号作为关系运算符“等于”。如在BASIC程序中可以写
if (a=3) then …
但C语言中,“=”是赋值运算符,“==”是关系运算符。如:
if (a==3) a=b;
前者是进行比较,a是否和3相等,后者表示如果a和3相等,把b值赋给a。由于习惯问题,初学者往往会犯这样的错误。
5.忘记加分号。
分号是C语句中不可缺少的一部分,语句末尾必须有分号。
a=1
b=2
编译时,编译程序在“a=1”后面没发现分号,就把下一行“b=2”也作为上一行语句的一部分,这就会出现语法错误。改错时,有时在被指出有错的一行中未发现错误,就需要看一下上一行是否漏掉了分号。
{ z=x+y;
t=z/100;
printf("%f",t);
}
对于复合语句来说,一个语句中的分号不能忽略不写(这是和PASCAL不同的)。
6.多加分号。
对于一个复合语句,如:
{ z=x+y;
t=z/100;
printf("%f",t);
};
复合语句的花括号后不应再加分号,否则将会画蛇添足。
又如:
if (a%3==0);
I++;
本是如果3整除a,则I加1。但由于if (a%3==0)后多加了分号,则if语句到此结束,程序将执行I++语句,不论3是否整除a,I都将自动加1。
再如:
for (I=0;I<5;I++);
{scanf("%d",&x);
printf("%d",x);}
本意是先后输入5个数,每输入一个数后再将它输出。由于for()后多加了一个分号,使循环体变为空语句,此时只能输入一个数并输出它。
7.输入变量时忘记加地址运算符“&”。
int a,b;
scanf("%d%d",a,b);
这是不合法的。Scanf函数的作用是:按照a、b在内存的地址将a、b的值存进去。“&a”指a在内存中的地址。
8.输入数据的方式与要求不符。①scanf("%d%d",&a,&b);
输入时,不能用逗号作两个数据间的分隔符,如下面输入不合法:
3,4
输入数据时,在两个数据之间以一个或多个空格间隔,也可用回车键,跳格键tab。
②scanf("%d,%d",&a,&b);
C规定:如果在“格式控制”字符串中除了格式说明以外还有其它字符,则在输入数据时应输入与这些字符相同的字符。下面输入是合法的:
3,4
此时不用逗号而用空格或其它字符是不对的。
3 4 3:4
又如:
scanf("a=%d,b=%d",&a,&b);
输入应如以下形式:
a=3,b=4
9.输入字符的格式与要求不一致。
在用“%c”格式输入字符时,“空格字符”和“转义字符”都作为有效字符输入。
scanf("%c%c%c",&c1,&c2,&c3);
如输入a b c
字符“a”送给c1,字符“ ”送给c2,字符“b”送给c3,因为%c只要求读入一个字符,后面不需要用空格作为两个字符的间隔。
10.输入输出的数据类型与所用格式说明符不一致。
例如,a已定义为整型,b定义为实型
a=3;b=4.5;
printf("%f%d\n",a,b);
编译时不给出出错信息,但运行结果将与原意不符。这种错误尤其需要注意。
11.输入数据时,企图规定精度。
scanf("%7.2f",&a);
这样做是不合法的,输入数据时不能规定精度。
12.switch语句中漏写break语句。
例如:根据考试成绩的等级打印出百分制数段。
switch(grade)
{ case 'A':printf("85~100\n");
case 'B':printf("70~84\n");
case 'C':printf("60~69\n");
case 'D':printf("<60\n");
default:printf("error\n");
由于漏写了break语句,case只起标号的作用,而不起判断作用。因此,当grade值为A时,printf函数在执行完个语句后接着执行第二、三、四、五个printf函数语句。正确写法应在每个分支后再加上“break;”。例如
case 'A':printf("85~100\n");break;
13.忽视了while和do-while语句在细节上的区别。
(1)main()
{int a=0,I;
scanf("%d",&I);
while(I<=10)
{a=a+I;
I++;
}
printf("%d",a);
}
(2)main()
{int a=0,I;
scanf("%d",&I);
do
{a=a+I;
I++;
}while(I<=10);
printf("%d",a);
}
可以看到,当输入I的值小于或等于10时,二者得到的结果相同。而当I>10时,二者结果就不同了。因为while循环是先判断后执行,而do-while循环是先执行后判断。对于大于10的数while循环一次也不执行循环体,而do-while语句则要执行一次循环体。
14.定义数组时误用变量。
int n;
scanf("%d",&n);
int a[n];
数组名后用方括号括起来的是常量表达式,可以包括常量和符号常量。即C不允许对数组的大小作动态定义。
15.在定义数组时,将定义的“元素个数”误认为是可使的下标值。
main()
{STatic int a[10]={1,2,3,4,5,6,7,8,9,10};
printf("%d",a[10]);
}
C语言规定:定义时用a[10],表示a数组有10个元素。其下标值由0开始,所以数组元素a[10]是不存在的。
16.初始化数组时,未使用静态存储。
int a[3]={0,1,2};
这样初始化数组是不对的。C语言规定只有静态存储(static)数组和外部存储(exterm)数组才能初始化。应改为:
static int a[3]={0,1,2};
17.在不应加地址运算符&的位置加了地址运算符。
scanf("%s",&str);
C语言编译系统对数组名的处理是:数组名代表该数组的起始地址,且scanf函数中的输入项是字符数组名,不必要再加地址符&。应改为:
scanf("%s",str);
18.同时定义了形参和函数中的局部变量。
int max(x,y)
int x,y,z;
{z=x>y?x:y;
return(z);
}
形参应该在函数体外定义,而局部变量应该在函数体内定义。应改为:
int max(x,y)
int x,y;
{int z;
z=x>y?x:y;
return(z);
}
编写高效简洁的C语言代码,是许多软件工程师追求的目标。本文就工作中的一些体会和经验做相关的阐述,不对的地方请各位指教。
第1招:以空间换时间
计算机程序中的矛盾是空间和时间的矛盾,那么,从这个角度出发逆向思维来考虑程序的效率问题,我们就有了解决问题的第1招——以空间换时间。
例如:字符串的赋值。
方法A,通常的办法:
#define LEN 32
char string1 [LEN];
memset (string1,0,LEN);
strcpy (string1,“This is a example!!”);
方法B:
const char string2[LEN] =“This is a example!”;
char * cp;
cp = string2 ;
(使用的时候可以直接用指针来操作。)
从上面的例子可以看出,A和B的效率是不能比的。在同样的存储空间下,B直接使用指针就可以操作了,而A需要调用两个字符函数才能完成。B的缺点在于灵活性没有A好。在需要频繁更改一个字符串内容的时候,A具有更好的灵活性;如果采用方法B,则需要预存许多字符串,虽然占用了大量的内存,但是获得了程序执行的高效率。
如果系统的实时性要求很高,内存还有一些,那我推荐你使用该招数。
该招数的变招——使用宏函数而不是函数。举例如下:
方法C:
#define bwMCDR2_ADDRESS 4
#define bsMCDR2_ADDRESS 17
int BIT_MASK(int __bf)
{
return ((1U << (bw ## __bf)) - 1) << (bs ## __bf);
}
void SET_BITS(int __dst, int __bf, int __val)
{
__dst = ((__dst) & ~(BIT_MASK(__bf))) \
(((__val) << (bs ## __bf)) & (BIT_MASK(__bf))))
}
SET_BITS(MCDR2, MCDR2_ADDRESS, RegisterNumber);
方法D:
#define bwMCDR2_ADDRESS 4
#define bsMCDR2_ADDRESS 17
#define bmMCDR2_ADDRESS BIT_MASK(MCDR2_ADDRESS)
#define BIT_MASK(__bf) (((1U << (bw ## __bf)) - 1) << (bs ## __bf))
#define SET_BITS(__dst, __bf, __val) \
((__dst) = ((__dst) & ~(BIT_MASK(__bf))) \
(((__val) << (bs ## __bf)) & (BIT_MASK(__bf))))
SET_BITS(MCDR2, MCDR2_ADDRESS, RegisterNumber);
函数和宏函数的区别就在于,宏函数占用了大量的空间,而函数占用了时间。大家要知道的是,函数调用是要使用系统的栈来保存数据的,如果编译器里有栈检查选项,一般在函数的头会嵌入一些汇编语句对当前栈进行检查;同时,CPU也要在函数调用时保存和恢复当前的现场,进行压栈和弹栈操作,所以,函数调用需要一些CPU时间。而宏函数不存在这个问题。宏函数仅仅作为预先写好的代码嵌入到当前程序,不会产生函数调用,所以仅仅是占用了空间,在频繁调用同一个宏函数的时候,该现象尤其突出。 D方法是我看到的的置位操作函数,是ARM公司源码的一部分,在短短的三行内实现了很多功能,几乎涵盖了所有的位操作功能。C方法是其变体,其中滋味还需大家仔细体会。
第2招:数学方法解决问题
现在我们演绎高效C语言编写的第二招——采用数学方法来解决问题。
数学是计算机之母,没有数学的依据和基础,就没有计算机的发展,所以在编写程序的时候,采用一些数学方法会对程序的执行效率有数量级的提高。
举例如下,求 1~100的和。
方法E
int I , j;
for (I = 1 ;I<=100; I ++){
j += I;
}
方法F
int I;
I = (100 * (1+100)) / 2
这个例子是我印象最深的一个数学用例,是我的计算机启蒙老师考我的。当时我只有小学三年级,可惜我当时不知道用公式 N×(N+1)/ 2 来解决这个问题。方法E循环了100次才解决问题,也就是说最少用了100个赋值,100个判断,200个加法(I和j);而方法F仅仅用了1个加法,1次乘法,1次除法。效果自然不言而喻。所以,现在我在编程序的时候,更多的是动脑筋找规律,限度地发挥数学的威力来提高程序运行的效率。 第3招:使用位操作
实现高效的C语言编写的第三招——使用位操作,减少除法和取模的运算。
在计算机程序中,数据的位是可以操作的最小数据单位,理论上可以用“位运算”来完成所有的运算和操作。一般的位操作是用来控制硬件的,或者做数据变换使用,但是,灵活的位操作可以有效地提高程序运行的效率。举例如下:
方法G
int I,J;
I = 257 /8;
J = 456 % 32;
方法H
int I,J;
I = 257 >>3;
J = 456 - (456 >> 4 << 4);
在字面上好像H比G麻烦了好多,但是,仔细查看产生的汇编代码就会明白,方法G调用了基本的取模函数和除法函数,既有函数调用,还有很多汇编代码和寄存器参与运算;而方法H则仅仅是几句相关的汇编,代码更简洁,效率更高。当然,由于编译器的不同,可能效率的差距不大,但是,以我目前遇到的MS C ,ARM C 来看,效率的差距还是不小。相关汇编代码就不在这里列举了。
运用这招需要注意的是,因为CPU的不同而产生的问题。比如说,在PC上用这招编写的程序,并在PC上调试通过,在移植到一个16位机平台上的时候,可能会产生代码隐患。所以只有在一定技术进阶的基础下才可以使用这招。
第4招:汇编嵌入
高效C语言编程的必杀技,第四招——嵌入汇编。 “在熟悉汇编语言的人眼里,C语言编写的程序都是垃圾”。这种说法虽然偏激了一些,但是却有它的道理。汇编语言是效率的计算机语言,但是,不可能靠着它来写一个操作系统吧?所以,为了获得程序的高效率,我们只好采用变通的方法 ——嵌入汇编,混合编程。
举例如下,将数组一赋值给数组二,要求每一字节都相符。
char string1[1024],string2[1024];
方法I
int I;
for (I =0 ;I<1024;I++)
*(string2 + I) = *(string1 + I)
方法J
#ifdef _PC_
int I;
for (I =0 ;I<1024;I++)
*(string2 + I) = *(string1 + I);
#else
#ifdef _ARM_
__asm
{
MOV R0,string1
MOV R1,string2
MOV R2,#0
loop:
LDMIA R0!, [R3-R11]
STMIA R1!, [R3-R11]
ADD R2,R2,#8
CMP R2, #400
BNE loop
}
#endif
方法I是最常见的方法,使用了1024次循环;方法J则根据平台不同做了区分,在ARM平台下,用嵌入汇编仅用128次循环就完成了同样的操作。这里有朋友会说,为什么不用标准的内存拷贝函数呢?这是因为在源数据里可能含有数据为0的字节,这样的话,标准库函数会提前结束而不会完成我们要求的操作。这个例程典型应用于LCD数据的拷贝过程。根据不同的CPU,熟练使用相应的嵌入汇编,可以大大提高程序执行的效率。 虽然是必杀技,但是如果轻易使用会付出惨重的代价。这是因为,使用了嵌入汇编,便限制了程序的可移植性,使程序在不同平台移植的过程中,卧虎藏龙,险象环生!同时该招数也与现代软件工程的思想相违背,只有在迫不得已的情况下才可以采用。切记,切记。
使用C语言进行高效率编程,我的体会仅此而已。在此以本文抛砖引玉,还请各位高手共同切磋。希望各位能给出更好的方法,大家一起提高我们的编程技巧。
C语言为我们定义了四种基本数据类型:整型,浮点型,指针以及聚合类型(数组和结构体等),在此基础上,我们就可以声明变量。我们平时经常说定义一个某种类型的变量,其实这样说不确切,应该说是声明变量。
变量声明的基本形式是:
说明符(一个或多个) 声明表达式列表
比如说:int a, b, c, d;
C语言中对指针的声明比较有代表性,我们来看一下:
比如声明一个指向int型的指针a:int *a;
这个语句表示表达式*a产生的结果类型是int,而我们又知道*操作符执行的是间接访问操作,所以可以推断a肯定是一个指向int的指针。
C语言在本质上是一种自由形式的语言,它给了程序员很大的空间,我们同样可以这样写:int* a,这个声明与int *a时一个意思,而且似乎更为清楚,a被声明为类型为int*的指针(实则不然),这会诱导我们这样声明三个指向int型的指针:
int* a, b, c;
也许你会很自然的以为这条语句把三个变量a、b、c都声明为指向整型的指针,但是事实上我们被它的形式愚弄了,星号实际上是表达式*a的一部分,只对这个标识符有用,a是一个指针,但是b和c都只是普通的整型而已,要声明三指针,这样写是可以的:
int *a, *b, *c;
从这个简单的例子我们可以看出C语言的声明规则多么具有迷惑性,呵呵,这也是C语言饱受批*的地方之一,但这决定与语言本身的设计哲学,我们无法改变,要想用好C语言,我们必须掌握它的语法规则。
我们再看一个例子:
int fun();
我们都知道它把f声明为一个函数,它的返回值是一个整数。
如果这样写:
int *fun();
要想推断出它的含义,我们必须知道*fun()是如何求值的。首先执行的是函数调用操作符(),因为它的优先级高于间接访问操作符*,所以fun是一个函数,它的返回值类型是一个指向整型的指针。
再看一个更为有趣的声明:
int (*fun)();
这个声明有两对括号,每对括号的含义不同。第二对括号是函数调用操作符,但是对只起到聚组的作用。它导致间接访问在函数调用之前进行,使fun是一个函数指针,它所指向的函数返回一个整型值。
那么现在这个声明应该很容易分析出来了
int *(*fun)();
fun还是一个函数指针,只是所指向的函数返回的是一个整型指针。
先写到这里,对C语言的声明之旅才刚刚开始,下回我们将在中级篇里讨论更有趣的话题!
C语言的声明存在的的问题就是你无法以一种人们所习惯的自然方式从左到右阅读一个声明,程序员必须记住特殊的规则才能推断出int *p[3]到底是一个int类型的指针数组还是一个指向int数组的指针。
对于这样一个声明,我们应该如何分析?
——————int f()[];
首先,f是一个函数,其次,它的返回值是一个整型数组。貌似就是这样啊,但实际上,这个例子隐藏着一个陷阱,因为这个声明是非法的,呵呵,在我们的C语言里,函数只能返回变量值,不能返回数组。
还有一个让人颇费脑筋的声明:
——————int f[] ();
这里,f应该是一个数组,数组的元素类型是返回值为整型的函数。请不要对它看似正确的表面所迷惑,其实这个声明也是非法的!因为数组元素必须具有相同的长度,但是不同的函数显然可能具有不同的长度吧,呵呵。
在被C语言迷幻的声明形式欺骗两次之后,现在是不是有些草木皆兵了?让我们乘热打铁,再看一个声明:
——————int (*f[]) ();
请你分析一下它的含义?首先,你能否确定它是对的还是错的?
首先,我们必须找到所有的操作符,然后按照正确的次序执行它们。这里有两对括号,它们分别具有不同的含义。个括号内的表达式*f[]首先进行求值,所以f是一个元素为某种类型的指针的数组;末尾的括号是函数调用操作符,所以我们可以肯定f是一个数组,数组元素的类型是函数指针,它所指向的函数的返回值是一个整型值。
清楚了上面这个声明,下面这个声明应该就比较容易分析了:
——————int *(*f[ ]) ( );
这个声明创建了一个指针数组,指针所指向的类型是返回值为整型指针的函数。
ANSI C推荐我们使用完整的函数原型,使声明更为明确,例如:
int (*f) ( int, float );
int *(*g[]) ( int, float );
前者把f声明为一个函数指针,它所指向的函数接受两个参数,分别是一个整型数和浮点型值,并返回一个整数。
后者把g声明为一个数组,数组的元素类型是一个函数指针,它所指向的函数接受两个参数,分别是一个整型数和浮点型值,并返回一个整型指针。尽管原型增加了声明的复杂度,但是ANSI C还是大力提倡这个风格,因为这样可以向编译器提供一些额外的信息。
在中级篇的,给大家推荐一个实用的C语言工具:cdecl,这个程序可用于所有UNIX操作系统,它可以将C语言的声明翻译成通俗易懂的语言,并可以将C语言声明的语法转换成为具体的C语言声明。
如果你是用的是ubuntu操作系统,那么你只需要执行sudo apt-get install cdecl就可以把cdecl工具安装到你的计算机上,对于别的unix操作系统,你同样可以下载源码包安装(comp.sources.unix.newsgroup)。
在shell终端,我们执行cdecl就可以进入cdecl>提示符,然后输入:explain int (*(*f)())[10]; 可以得到:

可以看到,cdecl为我们解释了int (*(*f)()) [10]这个声明的含义,有了这个工具,不管我们遇到怎样诡异的C语言声明,都可以从容应对了吧,当然,我们可以给cdecl一个声明的语法,把上面一段解释输入进去,就可以看到:

可见,cdecl又帮我们把这段通俗的解释转换成为的C语言的声明。
怎么样,这个工具是不是很好用,如果你的系统里面还没有这个工具的话,你是不是应该赶快安装一个呢?让它成为你学习C语言的好帮手吧。
C语言的设计哲学要求对象的声明形式和它的使用形式尽可能相似,比如一个int类型的指针数组被声明为int *p[3];并以*p[i]这样的表达式引用或者使用指针所指向的int数据,所以它的声明形式和使用形式非常相似。这样做的好处是各种不同操作符的优先级在“声明”和“使用”时是一样的,而缺点恰好在与C语言的操作符的优先级过于复杂(有15级或者更多,取决于你怎么算),这是C语言设计不当、过于复杂之处。
实际上有些关键字只能出现在声明中,而不是使用中,比如volatile和const等,这使得声明形式和使用形式能完全对的上号的例子越来越少了。如果想要把什么东西强制转换为指向数组的指针,就不得不使用下面的语句来表示这个强制类型转换:
———char (*j) [ 20 ];
———j = ( char ( * )[20] ) malloc(20);
这个强制类型转换看上去很滑稽,星号两边的括号看上去可有可无,但是如果去掉就会变成非法语句。
涉及指针和const得声明可能会有下面几种不同的组合:
———const int * p;
———int const * p;
———int * const p;
前两种情况,指针所指向的对象是只读的,而一种情况下指针是只读的。
如果我们想让对象和指针都是只读的,那么下面两种声明都能做到这一点:
———const int * const p;
———int const * const p;
经过初级篇、中级篇一直到前面的学习我们发现其实分析一个声明就是按照操作符优先级规则把声明分解开来,分别解释各个组成部分。要理解一个声明,必须要懂得其中的优先级规则,下面是《C专家编程》中总结的C语言声明的优先级规则:
A声明从它的名字开始读取,然后按照优先级顺序依次读取;
B 优先级从高到低依次是:
B.1 声明中被括号括起来的那部分;
B.2 后缀操作符:括号()表示这是一个函数,而方括号[]表示这是一个数组;
B.3 前缀操作符:星号*标识“指向……的指针”;
C 如果const和(或者)volatile关键字的后面紧跟类型说明符(如int,long等),那么它作用于类型说明符,在其他情况下,const和(或)volatile关键字作用于它左边紧邻的指针星号。
现在,让我们用优先级规则来分析C语言的一个较复杂的声明:
———char * const *(*next) ();
B.1 (*next) ——next为一个指向……的指针
B.2 (*next)() ——next是一个函数指针
B.3 *(*next)() ——next是一个函数指针,这个函数返回一个指向……的指针
C char * const ——指向字符类型的常量指针
故 char * const *(*next)();的含义就是:next是一个函数指针,这个函数返回一个指向字符类型的常量指针。
开发应用中,已逐渐开始引入语言,C语言就是其中的一种。对用惯了汇编的人来说,总觉得语言’可控性’不好,不如汇编那样随心所欲。但是只要我们掌握了一定的C语言知识,有些东西还是容易做出来的,以下是笔者实际工作中遇到的几个问题,希望对初学C51者有所帮助。
一、C51热启动代码的编制
对于工业控制计算机,往往设有有看门狗电路,当看门狗动作,使计算机复位,这就是热启动。热启动时,一般不允许从头开始,这将导致现有的已测量到或计算到的值复位,导致系统工作异常。因而在程序必须判断是热启动还是冷启动,常用的方法是:确定某内存单位为标志位(如0x7f位和0x7e位),启动时首先读该内存单元的内容,如果它等于一个特定的值(例如两个内存单元的都是0xaa),就认为是热启动,否则就是冷启动,程序执行初始化部份,并将0xaa赋与这两个内存单元。
根据以上的设计思路,编程时,设置一个指针,让其指向特定的内存单元如0x7f,然后在程序中判断,程序如下:
void main()
{ char data *HotPoint=(char *)0x7f;
if((*HotPoint==0xaa)&&(*(--HotPoint)==0xaa))
{ /*热启动的处理 */
}
else
{ HotPoint=0x7e; /*冷启动的处进
*HotPoint=0xaa;
*(++HotPoint)=0xaa;
}
/*正常工作代码*/
}
然而实际调试中发现,无论是热启动还是冷启动,开机后所有内存单元的值都被复位为0,当然也实现不了热启动的要求。这是为什么呢?原来,用C语言编程时,开机时执行的代码并非是从main()函数的句语句开始的,在main()函数的句语句执行前要先执行一段’起始代码’。正是这段代码执行了清零的工作。C编译程序提供了这段起始代码的源程序,名为CSTARTUP.A51,打开这个文件,可以看到如下代码:
.
IDATALEN EQU 80H ; the length of IDATA memory in bytes.
.
STARTUP1:
IF IDATALEN <> 0
MOV R0,#IDATALEN - 1
CLR A
IDATALOOP: MOV @R0,A
DJNZ R0,IDATALOOP
ENDIF
.
可见,在执行到判断是否热启动的代码之前,起始代码已将所有内存单元清零。如何解决这个问题呢?好在启动代码是可以更改的,方法是:修改 startup.a51源文件,然后用编译程序所附带的a51.exe程序对 startup.a51编译,得到startup.obj文件,然后用这段代码代替原来的起始代码。具体步骤是(设C源程序名为HOTSTART.C):
修改startup.a51源文件(这个文件在C51\LIB目录下)。
执行如下命令:
A51 startup.a51 得到startup.obj文件。将此文件拷入HOTSTART.C所在目录。
将编好的C源程序用C51.EXE编译好,得到目标文件HOTSTART.OBJ。
用 L51 HOTSTART, STARTUP.OBJ 命令连接,得到目标文件HOTSTART。
用 OHS51 HOTSTART 得到HOTSTART.HEX文件,即可。
对于startup.a51的修改,根据自已的需要进行,如将IDATALEN EQU 80H中的80H改为70H,就可以使6F到7F的16字节内存不被清零。
二、直接调用EPROM中已固化的程序
笔者用的仿真机,由6位数码管显示,在内存DE00H处放显示子程序,只要将要显示的数放入显示缓冲区,然后调用这个子程序就可以使用了,汇编指令为:
LCALL 0DEOOH
在用C语言编程时,如何实现这一功能呢?C语言中有指向函数的指针这一概念,可以利用这种指针来实现用函数指针调用函数。指向函数的指针变量的定义格式为:
类型标识符 (*指针变量名)();
在定义好指针后就可以给指针变量赋值,使其指向某个函数的开始存地址,然后用
(*指针变量名)()即可调用这个函数。如下例:
void main(void)
{
void (*DispBuffer)(); /*定义指向函数指针*/
DispBuffer=0xde00; /*赋值*/
for(;;)
{ Key();
DispBuffer();
}
}
三、将浮点数转化为字符数组
笔者在编制应用程序时有这样的要求:将运算的结果(浮点数)存入EEPROM中。我们知道,浮点数在C语言中是以IEEE格式存储的,一个浮点数占用四个字节,例如浮点数34.526存为(160,26,10,66)这四个数。要将一个浮点数存入EEPROM,实际上就是要存这四个数。那么如何在程序中得到一个浮点数的组成数呢?
浮点数在存储时,是存储连续的字节中的,只要设法找到存储位置,就可以得到这些数了。可以定义一个void的指针,将此指针指向需要存储的浮点数,然后将此指针强制转化为char型,这样,利用指针就可以得到组成该浮点数的各个字节的值了。具体程序如下:
#define uchar unsigned char#define uint unsigned intvoid FtoC(void)
{ float a;
uchar i,*px
uchar x[4]; /*定义字符数组,准备存储浮点数的四个字节*、
void *pf;
px=x; /*px指针指向数组x*/
pf=&a; /*void 型指针指向浮点数首地址*/
a=34.526;
for(i=0;i<4;i++)
{ *(px+i)=*((char *)pf+i); /*强制void 型指针转成char型,因为*/
} /*void型指针不能运算*/
}
如果已将数存入EEPROM,要将其取出合并,方法也是一样,可参考下面的程序。
#define uchar unsigned char#define uint unsigned int
void CtoF(void)
{ float a;
uchar i,*px
uchar x[4]={56,180,150,73};
void *pf;
px=x;
pf=&a;
for(i=0;i<4;i++)
{ *((char *)pf+i)=*(px+i);
}
}
以上所用C语言为FRANKLIN C51 VER 3.2。
链接过程要把我们编写的一个c程序(源代码)转换成可以在硬件上运行的程序(可执行代码),需要进行编译和链接。编译就是把文本形式源代码翻译为机器语言形式的目标文件的过程。链接是把目标文件、操作系统的启动代码和用到的库文件进行组织形成最终生成可执行代码的过程。过程图解如下:
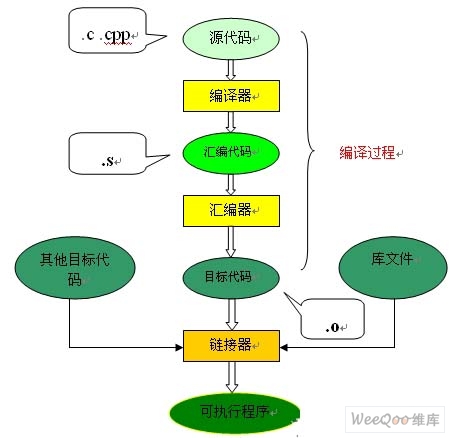
从图上可以看到,整个代码的编译过程分为编译和链接两个过程,编译对应图中的大括号括起的部分,其余则为链接过程。
编译过程
编译过程又可以分成两个阶段:编译和会汇编。
编译
编译是读取源程序(字符流),对之进行词法和语法的分析,将语言指令转换为功能等效的汇编代码,源文件的编译过程包含两个主要阶段:
个阶段是预处理阶段,在正式的编译阶段之前进行。预处理阶段将根据已放置在文件中的预处理指令来修改源文件的内容。如#include指令就是一个预处理指令,它把头文件的内容添加到.cpp文件中。这个在编译之前修改源文件的方式提供了很大的灵活性,以适应不同的计算机和操作系统环境的限制。一个环境需要的代码跟另一个环境所需的代码可能有所不同,因为可用的硬件或操作系统是不同的。在许多情况下,可以把用于不同环境的代码放在同一个文件中,再在预处理阶段修改代码,使之适应当前的环境。
主要是以下几方面的处理:
(1)宏定义指令,如 #define a b
对于这种伪指令,预编译所要做的是将程序中的所有a用b替换,但作为字符串常量的 a则不被替换。还有 #undef,则将取消对某个宏的定义,使以后该串的出现不再被替换。
(2)条件编译指令,如#ifdef,#ifndef,#else,#elif,#endif等。
这些伪指令的引入使得程序员可以通过定义不同的宏来决定编译程序对哪些代码进行处理。预编译程序将根据有关的文件,将那些不必要的代码过滤掉。
(3) 头文件包含指令,如#include "FileName"或者#include <FileName>等。
在头文件中一般用伪指令#define定义了大量的宏(最常见的是字符常量),同时包含有各种外部符号的声明。采用头文件的目的主要是为了使某些定义可以供多个不同的C源程序使用。因为在需要用到这些定义的C源程序中,只需加上一条#include语句即可,而不必再在此文件中将这些定义重复一遍。预编译程序将把头文件中的定义统统都加入到它所产生的输出文件中,以供编译程序对之进行处理。包含到c源程序中的头文件可以是系统提供的,这些头文件一般被放在 /usr/include目录下。在程序中#include它们要使用尖括号(< >)。另外开发人员也可以定义自己的头文件,这些文件一般与c源程序放在同一目录下,此时在#include中要用双引号("")。
(4)特殊符号,预编译程序可以识别一些特殊的符号。
例如在源程序中出现的LINE标识将被解释为当前行号(十进制数),FILE则被解释为当前被编译的C源程序的名称。预编译程序对于在源程序中出现的这些串将用合适的值进行替换。
预编译程序所完成的基本上是对源程序的“替代”工作。经过此种替代,生成一个没有宏定义、没有条件编译指令、没有特殊符号的输出文件。这个文件的含义同没有经过预处理的源文件是相同的,但内容有所不同。下一步,此输出文件将作为编译程序的输出而被翻译成为机器指令。
第二个阶段编译、优化阶段,经过预编译得到的输出文件中,只有常量;如数字、字符串、变量的定义,以及C语言的关键字,如main,if,else,for,while,{,}, +,-,*,\等等。
编译程序所要作得工作就是通过词法分析和语法分析,在确认所有的指令都符合语法规则之后,将其翻译成等价的中间代码表示或汇编代码。
优化处理是编译系统中一项比较艰深的技术。它涉及到的问题不仅同编译技术本身有关,而且同机器的硬件环境也有很大的关系。优化一部分是对中间代码的优化。这种优化不依赖于具体的计算机。另一种优化则主要针对目标代码的生成而进行的。
对于前一种优化,主要的工作是删除公共表达式、循环优化(代码外提、强度削弱、变换循环控制条件、已知量的合并等)、复写传播,以及无用赋值的删除,等等。
后一种类型的优化同机器的硬件结构密切相关,最主要的是考虑是如何充分利用机器的各个硬件寄存器存放的有关变量的值,以减少对于内存的访问次数。另外,如何根据机器硬件执行指令的特点(如流水线、RISC、CISC、VLIW等)而对指令进行一些调整使目标代码比较短,执行的效率比较高,也是一个重要的研究课题。
汇编
汇编实际上指把汇编语言代码翻译成目标机器指令的过程。对于被翻译系统处理的每一个C语言源程序,都将最终经过这一处理而得到相应的目标文件。目标文件中所存放的也就是与源程序等效的目标的机器语言代码。目标文件由段组成。通常一个目标文件中至少有两个段:
代码段:该段中所包含的主要是程序的指令。该段一般是可读和可执行的,但一般却不可写。
数据段:主要存放程序中要用到的各种全局变量或静态的数据。一般数据段都是可读,可写,可执行的。
UNIX环境下主要有三种类型的目标文件:
(1)可重定位文件
其中包含有适合于其它目标文件链接来创建一个可执行的或者共享的目标文件的代码和数据。
(2)共享的目标文件
这种文件存放了适合于在两种上下文里链接的代码和数据。种是链接程序可把它与其它可重定位文件及共享的目标文件一起处理来创建另一个 目标文件;第二种是动态链接程序将它与另一个可执行文件及其它的共享目标文件结合到一起,创建一个进程映象。
(3)可执行文件
它包含了一个可以被操作系统创建一个进程来执行之的文件。汇编程序生成的实际上是种类型的目标文件。对于后两种还需要其他的一些处理方能得到,这个就是链接程序的工作了。
链接过程
由汇编程序生成的目标文件并不能立即就被执行,其中可能还有许多没有解决的问题。
例如,某个源文件中的函数可能引用了另一个源文件中定义的某个符号(如变量或者函数调用等);在程序中可能调用了某个库文件中的函数,等等。所有的这些问题,都需要经链接程序的处理方能得以解决。
链接程序的主要工作就是将有关的目标文件彼此相连接,也即将在一个文件中引用的符号同该符号在另外一个文件中的定义连接起来,使得所有的这些目标文件成为一个能够诶操作系统装入执行的统一整体。
根据开发人员指定的同库函数的链接方式的不同,链接处理可分为两种:
(1)静态链接
在这种链接方式下,函数的代码将从其所在地静态链接库中被拷贝到最终的可执行程序中。这样该程序在被执行时这些代码将被装入到该进程的虚拟地址空间中。静态链接库实际上是一个目标文件的集合,其中的每个文件含有库中的一个或者一组相关函数的代码。
(2) 动态链接
在此种方式下,函数的代码被放到称作是动态链接库或共享对象的某个目标文件中。链接程序此时所作的只是在最终的可执行程序中记录下共享对象的名字以及其它少量的登记信息。在此可执行文件被执行时,动态链接库的全部内容将被映射到运行时相应进程的虚地址空间。动态链接程序将根据可执行程序中记录的信息找到相应的函数代码。
对于可执行文件中的函数调用,可分别采用动态链接或静态链接的方法。使用动态链接能够使最终的可执行文件比较短小,并且当共享对象被多个进程使用时能节约一些内存,因为在内存中只需要保存一份此共享对象的代码。但并不是使用动态链接就一定比使用静态链接要优越。在某些情况下动态链接可能带来一些性能上损害。
我们在linux使用的gcc编译器便是把以上的几个过程进行捆绑,使用户只使用一次命令就把编译工作完成,这的确方便了编译工作,但对于初学者了解编译过程就很不利了,下图便是gcc代理的编译过程:

从上图可以看到:
预编译
将.c 文件转化成 .i文件
使用的gcc命令是:gcc –E
对应于预处理命令cpp
编译
将.c/.h文件转换成.s文件
使用的gcc命令是:gcc –S
对应于编译命令 cc –S
汇编
将.s 文件转化成 .o文件
使用的gcc 命令是:gcc –c
对应于汇编命令是 as
链接
将.o文件转化成可执行程序
使用的gcc 命令是: gcc
对应于链接命令是 ld
总结起来编译过程就上面的四个过程:预编译、编译、汇编、链接。Lia了解这四个过程中所做的工作,对我们理解头文件、库等的工作过程是有帮助的,而且清楚的了解编译链接过程还对我们在编程时定位错误,以及编程时尽量调动编译器的检测错误会有很大的帮助的。
维库电子通,电子知识,一查百通!
已收录词条937245个