Linux是一套免费使用和自由传播的操作系统,它主要用于基于Intel系列CPU的计算机上。这个系统是由全世界各地的成千上万的程序员设计和实现的,其目的是建立不受任何商品化软件的版权制约的、全世界都能自由使用的Unix兼容产品。
实时系统指系统的计算正确性不仅取决于计算的逻辑正确性,还取决于产生结果的时间。如果未满足系统的时间约束,则认为系统失效。换句话说,系统面对变化的负载(从最小到最坏的情况)时必须确定性地保证满足时间要求。 注意,实时性与速度关系不大:它与可预见性有关。例如,使用快速的现代处理器时,Linux 可以提供 20 μ 微秒的典型中断响应,但有时候响应会变得很长。这是一个基本的问题:并不是 Linux 不够快或效率不够高,而是因为它不能提供确定性。 当中断到达时(event),CPU 发生中断并转入中断处理。执行一些工作以确定发生了什么事件,然后执行少量工作分配必需的任务以处理此事件(上下文切换)。中断到达与分发必需任务之间的时间(假设分配的是优先级的任务)称为响应时间。对于实时性要求,响应时间应是确定的并应当在已知的最坏情况的时间内完成。因此,对于某些高安全性的场合,操作系统应快速地分配任务,并且不允许其他非实时处理进行干扰。晚一秒钟响应比没有响应的情况更糟糕。 除为中断处理提供确定性外,实时处理也需要支持周期性间隔的任务调度。大量控制系统要求周期性采样与处理。某个特定任务必须按照固定的周期(p)执行,从而确保系统的稳定性。在某些控制场合下,为了保持控制系统的正常工作,传感器的采样与控制必须按照一定的周期间隔。这意味着必须抢占其他处理,以便特定任务能按照期望的周期执行。 能够在指定的期限完成实时任务(即便在最坏的处理负载下也能如此)的操作系统称为硬实时 系统。但并不是任何情况下都需要硬实时支持。如果操作系统在平均情况下能支持任务的执行期限,则称它为软实时 系统。硬实时系统指超过截止期限后将造成灾难性后果(例如展开气囊过晚或制动压力产生的滑行距离过长)的系统。软实时系统超过截止期限后并不会造成系统整体失败(如丢失视频中的一帧)。 Linux 架构支持通过以下几种方式实现硬实时。 1. 瘦内核方法 瘦内核(或微内核)方法使用了第二个内核作为硬件与 Linux 内核间的抽象接口。非实时 Linux 内核在后台运行,作为瘦内核的一项低优先级任务托管全部非实时任务。实时任务直接在瘦内核上运行。 瘦内核主要用于(除了托管实时任务外)中断管理。瘦内核截取中断以确保非实时内核无法抢占瘦内核的运行。这允许瘦内核提供硬实时支持。 虽然瘦内核方法有自己的优势(硬实时支持与标准 Linux 内核共存),但这种方法也有缺点。实时任务和非实时任务是独立的,这造成了调试困难。而且,非实时任务并未得到 Linux 平台的完全支持(瘦内核执行称为瘦 的一个原因)。 使用这种方法的例子有 RTLinux。 2. 超微内核方法 瘦内核方法依赖于包含任务管理的最小内核,而超微内核法对内核进行更进一步的缩减。通过这种方式,它不像是一个内核而更像是一个硬件抽象层(HAL)。超微内核为运行于更别的多个操作系统提供了硬件资源共享。 这种方法和运行多个操作系统的虚拟化方法有一些相似之处。使用这种方法的情况下,超微内核在实时和非实时内核中对硬件进行抽象。这与 hypervisor 从客户(guest)操作系统对裸机进行抽象的方式很相似。 3. 资源内核法 这种方法为内核增加一个模块,为各种资源提供预留(reservation)。这种机制保证了对时分复用(time-multiplexed)系统资源的访问(CPU、网络或磁盘带宽)。这些资源拥有多个预留参数,如循环周期、需要的处理时间(也就是完成处理所需的时间),以及截止时间。 资源内核提供了一组应用程序编程接口(API),允许任务请求这些预留资源。然后资源内核可以合并这些请求,使用任务定义的约束定义一个调度,从而提供确定的访问(如果无法提供确定性则返回错误)。通过调度算法,内核可以处理动态的调度负载。 资源内核法实现的一个示例是 CMU 公司的 Linux/RK,它把可移植的资源内核集成到 Linux 中作为一个可加载模块。这种实现演化成商用的 TimeSys Linux/RT 产品。
Linux的系统管理主要在控制终端下进行,通过使用命令行的方式进行管理。Linux的文件命令可以完成各种复杂的工作,例如对目录进行复制、移动和链接,搜索和查找文件和目录,阅读、显示或打印文件内容等操作。Linux操作系统提供的命令很多,但用户日常使用的命令却很有限。一些在日常工作中最常用的Linux命令:
熟练使用文件管理命令
熟练使用磁盘管理命令
熟练使用文件搜索和压缩/解压缩命令
熟练使用系统管理命令
区分Linux命令和DOS命令
Linux系统下的shell命令要比Windows下的DOS命令重要得多,因为完全可以不使用DOS命令而在Windows系统下完成所有的操作,但是在Linux系统下,很多shell命令在X Window图形窗口下是无法完成的,并且shell命令要比DOS命令更强大,相对也较复杂。
两者的区别主要有以下几点。
DOS的文件名必须遵循7.3规则,而Linux则支持ext3文件系统,可以支持长文件名,并且可以使用更多的“.”和字符。例如,abc.123.c在Linux系统下是一个合法的文件名。在Linux系统下,英文字母的大小写是不一样的。这个规则对于shell命令也是有效的。Linux下的文件如果是以“.”作为文件名的个字符,将会被认为是隐藏文件,使用ls命令是看不到这类文件的(用ls –a可以看到隐藏文件)。
Linux系统下的路径是用“/”分隔开的,而DOS下则用“\”分隔。Linux系统没有定义可执行文件的扩展名必须为.exe、.com、.bat等。用户使用命令ls –F可看到有的文件名后加了一个*号,那么这个文件就是可执行文件。
对于命令参数的应用也有不同之处。DOS下的参数和命令之间用“/”分隔,而在Linux系统下,命令和参数之间用“-”分隔,例如ls –l和dir/w。关于Linux与DOS的异同见表所示。
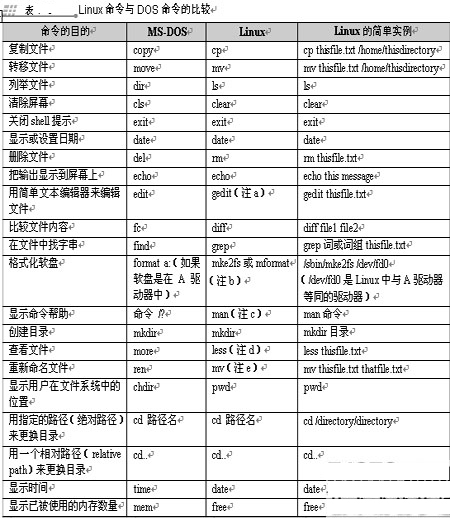
注:
a Gedit是图形化文本编辑器,也可以使用其他文本编辑器来代替Gedit,例如Emacs和vi等。
b 这个命令为DOS文件系统下格式化软盘的命令。
c 某些命令还可以使用info。
d more分页器也可以用来在文件中逐页查看。
e mv命令可以转移文件或重新命名同一目录下的文件。如果想重新命名文件,可把这个文件“转移”到同一目录中的新名称。
在 Linux 内核内,进程是由相当大的一个称为 task_struct 的结构表示的。此结构包含所有表示此进程所必需的数据,此外,还包含了大量的其他数据用来统计(accounting)和维护与其他进程的关系(父和子)。下面给出了 task_struct 的一小部分。task_struct 位于 ./linux/include/linux/sched.h。
struct task_struct {
volatile long state;
void *stack;
unsigned int flags;
int prio, static_prio;
struct list_head tasks;
struct mm_struct *mm, *active_mm;
pid_t pid;
pid_t tgid;
struct task_struct *real_parent;
char comm[TASK_COMM_LEN];
struct thread_struct thread;
struct files_struct *files;
...
};
在task_struct中,可以看到几个预料之中的项,比如执行的状态、堆栈、一组标志、父进程、执行的线程(可以有很多)以及开放文件。对其做简单声明如下
<1> state 变量是一些表明任务状态的比特位。最常见的状态有:
1.TASK_RUNNING 表示进程正在运行,或是排在运行队列中正要运行
2.TASK_INTERRUPTIBLE 表示进程正在休眠
3.TASK_UNINTERRUPTIBLE 表示进程正在休眠但不能叫醒
4.TASK_STOPPED 表示进程停止
注:这些标志的完整列表可以在 ./linux/include/linux/sched.h 内找到。
<2> flags 定义了很多指示符,表明进程是否正在被创建(PF_STARTING)或退出(PF_EXITING),或是进程当前是否在分配内存(PF_MEMALLOC)。
<3> 每个进程都会被赋予优先级(称为 static_prio),但进程的实际优先级是基于加载以及其他几个因素动态决定的。优先级值越低,实际的优先级越高。
<4> tasks 字段提供了链接列表的能力。它包含一个 prev 指针(指向前一个任务)和一个 next 指针(指向下一个任务)。
<5> 进程的地址空间由 mm 和 active_mm 字段表示。mm 代表的是进程的内存描述符,而 active_mm 则是前一个进程的内存描述符(为改进上下文切换时间的一种优化)。
<6> 可执行程序的名称(不包含路径)占用 comm(命令)字段。
<7> thread_struct 则用来标识进程的存储状态。此元素依赖于 Linux 在其上运行的特定架构,在 ./linux/include/asm-i386/processor.h 内有这样的一个例子。在此结构内,可以找到该进程自执行上下文切换后的存储(硬件注册表、程序计数器等)。
在很多情况下,进程都是动态创建并由一个动态分配的 task_struct 表示。当然 init 进程例外,它总是存在并由一个静态分配的 task_struct 表示。
Linux 内所有进程的分配有两种方式。种方式是通过一个哈希表,由 PID 值进行哈希计算得到;第二种方式是通过双链循环表。循环表非常适合于对任务列表进行迭代。由于列表是循环的,没有头或尾;但是由于 init_task 总是存在,所以可以将其用作继续向前迭代的一个锚点。
任务列表无法从用户空间访问,但该问题很容易解决,方法是以模块形式向内核内插入代码。例如通过如下代码,它会迭代任务列表并会提供有关每个任务的少量信息(name、pid 和 parent 名)。
struct task_struct *task = &init_task;
/* Walk through the task list, until we hit the init_task again */
do {
printk( KERN_INFO "*** %s [%d] parent %s\n",
task->comm, task->pid, task->parent->comm );
} while ( (task = next_task(task)) != &init_task );
注意,还可以标识当前正在运行的任务。Linux 维护一个称为 current 的符号,代表的是当前运行的进程(类型是 task_struct)。为此可使用如下代码:
printk( KERN_INFO, "Current task is %s [%d]”, current->comm, current->pid );
Linux创建用户空间进程的情况与内核空间进程类似。二者底层机制是一致的,因为最终都会依赖于一个名为 do_fork 的函数来创建新进程。
在创建内核线程时,内核会调用一个名为 kernel_thread 的函数(参见 ./linux/arch/i386/kernel/process.c),此函数执行某些初始化后会调用 do_fork。
在用户空间,一个程序会调用 fork,这会导致对名为 sys_fork 的内核函数的系统调用(参见 ./linux/arch/i386/kernel/process.c)。
do_fork 是进程创建的基础。可以在 ./linux/kernel/fork.c 内找到 do_fork 函数(以及相关函数 copy_process)。
do_fork 函数首先调用 alloc_pidmap,该调用会分配一个新的 PID。接下来,do_fork 检查调试器是否在跟踪父进程。如果是,在 clone_flags 内设置 CLONE_PTRACE 标志以做好执行 fork 操作的准备。之后 do_fork 函数还会调用 copy_process,向其传递这些标志、堆栈、注册表、父进程以及分配的 PID。
新的进程在 copy_process 函数内作为父进程的一个副本创建。此函数能执行除启动进程之外的所有操作,启动进程在之后进行处理。copy_process 内的步是验证 CLONE 标志以确保这些标志是一致的。如果不一致,就会返回 EINVAL 错误。接下来,询问 Linux Security Module (LSM) 看当前任务是否可以创建一个新任务。
接下来,调用 dup_task_struct 函数(./linux/kernel/fork.c ),这会分配一个新 task_struct 并将当前进程的描述符复制到其内。在新的线程堆栈设置好后,一些状态信息也会被初始化,并且会将控制返回给 copy_process。控制回到 copy_process 后,除了其他几个限制和安全检查之外,还会执行一些常规管理,包括在新 task_struct 上的各种初始化。之后,会调用一系列复制函数来复制此进程的各个方面,比如复制开放文件描述符(copy_files)、复制符号信息(copy_sighand 和 copy_signal)、复制进程内存(copy_mm)以及最终复制线程(copy_thread)。
之后,这个新任务会被指定给一个处理程序,同时对允许执行进程的处理程序进行额外的检查(cpus_allowed)。新进程的优先级从父进程的优先级继承后,执行一小部分额外的常规管理,而且控制也会被返回给 do_fork。在此时,新进程存在但尚未运行。do_fork 函数通过调用 wake_up_new_task 来修复此问题。此函数(./linux/kernel/sched.c )初始化某些调度程序的常规管理信息,将新进程放置在运行队列之内,然后将其唤醒以便执行。,一旦返回至 do_fork,此 PID 值即被返回给调用程序,进程完成。
在Linux设备驱动中,设备号设一个很重要的概念和变量。不论是主设备号,还是次设备号,在设备驱动中都占据了很重要的地位。那么他在Kernel中是如何操作的?这个数据结构都是通过那些函数可以很容易的在我们写Linux设备驱动模块时被我们所使用呢?
在include/linux/type.h文件中我们能看到一个关于dev_t的定义如下:
...
typedef __u32 __kernel_dev_t;
typedef __kernel_fd_set fd_set;
typedef __kernel_dev_t dev_t;
...
从这个定义中我们能看到dev_t是一个无符号的32位的整型。
首先我们需要说明的是,在linux中主次设备号是放置在一个无符号的32位的整型中,那么这32位整型对于主次设备号如何分配呢?
从源代码中我们可以看到,主设备号占据12个位,次设备好占据20位。这在一定的时期内,主次设备号是完全可以满足系统需要的。
同时在include/linux/kdev_t.h文件中我们能发现很多函数或者宏定义的操作都是针对dev_t的。
具体可以看到我们经常用到的MAJOR(dev)、MINOR(dev)、MKDEV(ma,mi)。
下面我们就具体分析下这三个我们经常用到的宏定义:
#define MINORBITS 20
#define MINORMASK ((1U << MINORBITS) - 1)
#define MAJOR(dev) ((unsigned int) ((dev) >> MINORBITS))
从这个宏定义中我们可以看到其把无符号的32位的整型做位操作运算:右移20位。
在C语言中如果是右移,那么左边补0,这样在这32位的整型中通过这个操作就只保留了原先第19位到31位的有效值,而这也正是我们所需要的。
下面我们看下MINOR这个宏定义:
#define MINOR(dev) ((unsigned int) ((dev) & MINORMASK))
要明白这个宏定义的具体是多少,我们需要首先明白宏定义MINORMASK是什么?
我们从前面的宏定义中,我们看到:
#define MINORMASK ((1U << MINORBITS) - 1)
MINORMASK 是1U也就是1左移位20个字节,二进制的话就是10000000000000000000,也就是1后面带20个0。
然后在减1呢,就成了二进制11111111111111111111,也就是20个1,十六进制的话是0xFFFFF。
好现在我们知道MINORMASK是20个1,也就是十六进制0xFFFFF,那么我们在与dev_t做一个位的与运算,就把32位中的前12为置0,保留其后面的20位,也正是我们想要的表是设备次设备号的后20个字节。
好下面我们看下如果我们知道了主设备号、次设备号,我们如何生成一个dev_t的数据结构。
宏定义:
#define MKDEV(ma,mi) (((ma) << MINORBITS) | (mi))
明白了前面我们所说的,其实这个就比较简单了,把主设备号左移20位,然后与上次设备号,就是我们所需要的dev_t的数据结构。
那么我们前面所说的关于dev_t的操作是新的2.6.x系列中的,在之前的2.4.x系列中,由于对设备号的总共就16个字节,也就是一个短整型,那么一个系统中所能拥有的设备号就是及其有限的了。
我们看下在老版本中的内核中他们的表示:
#define MAJOR(dev) ((dev)>>8)
#define MINOR(dev) ((dev) & 0xff)
#define MKDEV(ma,mi) ((ma)<<8 | (mi))
从中我们可以看出,他是以8为为分界线,高8位为主设备号,低8位为次设备号,那么一个8位所能表示的最多也即是255个数值,那么当我们系统中如果拥有的设备大于这个数值的时候,在老版本的内核中就没有办法处理了。
在内核实现中还实现了两个打印的函数,其实也是宏定义:
#define print_dev_t(buffer, dev) \
sprintf((buffer), "%u:%u\n", MAJOR(dev), MINOR(dev))
#define format_dev_t(buffer, dev) \
({ \
sprintf(buffer, "%u:%u", MAJOR(dev), MINOR(dev)); \
buffer; \
})
从代码中我们可以看出。
就是把设备的主设备号和次设备号以字符串的形式存放到buffer中,在使用这个宏定义的时候需要注意的是:
buffer需要提前开辟空间,而且还需要是够用的空间。
第二所实现的功能和个很类似。这儿我们就不具体说明,请参考个宏定义的实现。
在这个文件中还有很多的函数,这些函数的主要功能就是和老版本的内核代码兼容而产生的,比如:
static inline int old_valid_dev(dev_t dev)
{
return MAJOR(dev) < 256 && MINOR(dev) < 256;
}
此函数是判断一个dev_t是否可以转换成旧制的dev_t。
static inline u16 old_encode_dev(dev_t dev)
{
return (MAJOR(dev) << 8) | MINOR(dev);
}
把32位的设备号转换成16位的旧制的设备号。
其中主要操作为:首先把主设备号左移8位,为次设备好空出8位的位置,然后与上次设备号。
在使用这个函数的时候需要注意的就是需要首先判断下32位的设备号是否可以有效的转换成16位的设备号。
static inline dev_t old_decode_dev(u16 val)
{
return MKDEV((val >> 8) & 255, val & 255);
}
上面函数的反操作。
主设备号右移8位,然后与上255,即8个1。也就是取此变量的低8位,
次设备号与上255,也是取此变量的低8位即可。
static inline u32 new_encode_dev(dev_t dev)
{
unsigned major = MAJOR(dev);
unsigned minor = MINOR(dev);
return (minor & 0xff) | (major << 8) | ((minor & ~0xff) << 12);
^^^^^^^^^^^^^
次设备号取其低8位 ^^^^^^^^^^^^^^
主设备号左移8位。
^^^^^^^^^^^^^^^^^^^^^^^
次设备号低8位清零,左移12位。
}
static inline dev_t new_decode_dev(u32 dev)
{
unsigned major = (dev & 0xfff00) >> 8;
unsigned minor = (dev & 0xff) | ((dev >> 12) & 0xfff00);
return MKDEV(major, minor);
}
系统
根文件系统首先是一种文件系统,但是相对于普通的文件系统,它的特殊之处在于,它是内核启动时所mount的个文件系统,内核代码映像文件保存在根文件系统中,而系统引导启动程序会在根文件系统挂载之后从中把一些基本的初始化脚本和服务等加载到内存中去运行。
我们首先从主机上所安装的Linux操作系统中了解一些根文件系统的信息。比如在笔者工作的Linux桌面系统中可以得到下面的结果:
# mount
/dev/hda2 on / type ext3 (rw)
none on /proc type proc (rw)
/dev/hda1 on /boot type ext3 (rw)
none on /dev/pts type devpts (rw,gid=5,mode=620)
none on /dev/shm type tmpfs (rw)
# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/hda2 16216016 5667* 9724600 37% /
/dev/hda1 101089 9321 8*9 10% /boot
none 63028 0 63028 0% /dev/shm
从上面的mount命令我们可以看到,在桌面Linux中,根文件系统”/”被mount到/dev/hda2设备上,文件系统类型为ext3,属性为rw即可读写。从df命令则可以得到更多根文件系统使用空间的相关信息。
根文件系统一直以来都是所有类Unix操作系统的一个重要组成部分,也可以认为是嵌入式Linux系统区别于其他一些传统嵌入式操作系统的重要特征,它给Linux带来了许多强大和灵活的功能,同时也带来了一些复杂性。我们需要清楚的了解根文件系统的基本结构,以及细心的选择所需要的系统库、内核模块和应用程序等,并配置好各种初始化脚本文件,以及选择合适的文件系统类型并把它放到实际的存储设备的合适位置。
根文件系统的基本目录结构
Linux的根文件系统以树型结构组织,包含内核和系统管理所需要的各种文件和程序,一般说来根目录”/”下的顶层目录都有一些比较固定命名和用途。
下面列出了一个Linux根文件系统中的比较常见的目录结构:
/bin 存放二进制可执行命令的目录
/dev 存放设备文件的目录
/etc 存放系统管理和配置文件的目录
/home 用户主目录,比如用户user的主目录就是/home/user,可以用~user表示
/lib 存放动态链接共享库的目录
/sbin存放系统管理员使用的管理程序的目录
/tmp 公用的临时文件存储点
/root 系统管理员的主目录
/mnt 系统提供这个目录是让用户临时挂载其他的文件系统。
/proc 虚拟文件系统,可直接访问这个目录来获取系统信息。
/var 某些大文件的溢出区
/usr 最庞大的目录,要用到的应用程序和文件几乎都在这个目录。
对于经常使用Linux系统的读者来说,这些目录大部分应该很熟悉了。不过有几个目录对初学者来说容易混淆,如/bin,/sbin,/usr/bin和/usr/sbin。这里简单介绍一下它们的区别:/bin目录一般存放对于用户和系统来说都是必须的二进制文件,而/sbin目录要存放的是只针对系统管理的二进制文件,该目录的文件将不会被普通用户使用。相反,那些不是必要的用户二进制文件存放在/usr/bin下面,那些不是非常必要的系统管理工具放在/usr/sbin下。此外,对于一些本地的库也非常类似,对于那些要求启动系统和运行的必须命令要存放在/lib目录下,而对于其他不是必须的库存放在/usr/lib目录就可以。
对于嵌入式Linux系统的根文件系统来说,一般可能没有上面所列出的那么复杂,比如嵌入式系统通常都不是针对多用户的,所以/home这个目录在一般嵌入式Linux中可能就很少用到,而/boot这个目录则取决于你所使用的BootLoader是否能够重新获得内核映象从你的根文件系统在内核启动之前。一般说来,只有/bin,/dev,/etc,/lib,/proc,/var,/usr这些需要的,而其他都是可选的。
(一) 理解Linux下进程的结构
Linux下一个进程在内存里有三部份的数据,就是“数据段”,“堆栈段”和“代码段”,其实学过汇编语言的人一定知道,一般的CPU象I386,都有上述三种段寄存器,以方便操作系统的运行。“代码段”,顾名思义,就是存放了程序代码的数据,假如机器中有数个进程运行相同的一个程序,那么它们就可以使用同一
个代码段。
堆栈段存放的就是子程序的返回地址、子程序的参数以及程序的局部变量。而数据段则存放程序的全局变量,常数以及动态数据分配的数据空间(比如用malloc之类的函数取得的空间)。这其中有许多细节问题,这里限于篇幅就不多介绍了。系统如果同时运行数个相同的程序,它们之间就不能使用同一个堆栈段和数据 段。
(二) 如何使用fork
在Linux下产生新的进程的系统调用就是fork函数,这个函数名是英文中“分叉”的意思。为什么取这个名字呢?因为一个进程在运行中,如果使用了fork,就产生了另一个进程,于是进程就“分叉”了,所以这个名字取得很形象。下面就看看如何具体使用fork,这段程序演示了使用fork的基本框架:
void main(){
int i;
if ( fork() == 0 ) {
/* 子进程程序 */
for ( i = 1; i < 1000; i )
printf("This is child process\n");
}
else {
/* 父进程程序*/
for ( i = 1; i < 1000; i )
printf("This is process process\n");
}
}
程序运行后,你就能看到屏幕上交替出现子进程与父进程各打印出的一千条信息了。如果程序还在运行中 ,你用ps命令就能看到系统中有两个它在运行了。
那么调用这个fork函数时发生了什么呢?一个程序一调用fork函数,系统就为一个新的进程准备了前述三个段,首先,系统让新的进程与旧的进程使用同一个代码段,因为它们的程序还是相同的,对于数据段和堆栈段,系统则复制一份给新的进程,这样,父进程的所有数据都可以留给子进程,但是,子进程一旦开始运行,虽然它继承了父进程的一切数据,但实际上数据却已经分开,相互之间不再有影响了,也就是说,它们之间不再共享任何数据了。而如果两个进程要共享什么数据的话,就要使用另一套函数(shmget,shmat,shmdt等)来操作。现在,已经是两个进程了,对于父进程,fork函数返回了子程序的进程号,而对于子程序,fork函数则返回零,这样,对于程序,只要判断fork函数的返回值,就知道自己是处于父进程还是子进程中。
读者也许会问,如果一个大程序在运行中,它的数据段和堆栈都很大,一次fork就要复制一次,那么fork 的系统开销不是很大吗?其实UNIX自有其解决的办法,大家知道,一般CPU都是以“页”为单位分配空间的,象INTEL的CPU,其一页在通常情况下是4K字节大小,而无论是数据段还是堆栈段都是由许多“页”构成的, fork函数复制这两个段,只是“逻辑”上的,并非“物理”上的,也就是说,实际执行fork时,物理空间上两个进程的数据段和堆栈段都还是共享着的,当有一个进程写了某个数据时,这时两个进程之间的数据才有了区别,系统就将有区别的“页”从物理上也分开。系统在空间上的开销就可以达到最小。
一个小幽默:下面演示一个足以"搞死"Linux的小程序,其源代码非常简单:
void main()
{
for(;;) fork();
}
这个程序什么也不做,就是死循环地fork,其结果是程序不断产生进程,而这些进程又不断产生新的进程,很快,系统的进程就满了,系统就被这么多不断产生的进程"撑死了"。用不着是root,任何人运行上述程序都足以让系统死掉。哈哈,但这不是Linux不安全的理由,因为只要系统管理员足够聪明,他(或她)就可以预先给每个用户设置可运行的进程数,这样,只要不是root,任何能运行的进程数也许不足系统总的能运行和进程数的十分之一,这样,系统管理员就能对付上述恶意的程序了。
(三) 如何启动另一程序的执行
下面我们来看看一个进程如何来启动另一个程序的执行。在Linux中要使用exec类的函数,exec类的函数不止一个,但大致相同,在Linux中,它们分别是:execl,execlp,execle,execv,execve和execvp,下面我只以execlp为例,其它函数究竟与execlp有何区别,请通过manexec命令来了解它们的具体情况。
一个进程一旦调用exec类函数,它本身就“死亡”了,系统把代码段替换成新的程序的代码,废弃原有的数据段和堆栈段,并为新程序分配新的数据段与堆栈段,留下的,就是进程号,也就是说,对系统而言,还是同一个进程,不过已经是另一个程序了。(不过 exec类函数中有的还允许继承环境变量之类的信息。)
那么如果我的程序想启动另一程序的执行但自己仍想继续运行的话,怎么办呢?那就是结合fork与exec的 使用。下面一段代码显示如何启动运行其它程序:
char command[256];
void main()
{
int rtn; /*子进程的返回数值*/
while(1) {
/* 从终端读取要执行的命令 */
printf( ">" );
fgets( command, 256, stdin );
command[strlen(command)-1] = 0;
if ( fork() == 0 ) {
/* 子进程执行此命令 */
execlp( command, command );
/* 如果exec函数返回,表明没有正常执行命令,打印错误信息*/
perror( command );
exit( errorno );
}
else {
/* 父进程, 等待子进程结束,并打印子进程的返回值 */
wait ( &rtn );
printf( " child process return %d\n",. rtn );
}
}
}
此程序从终端读入命令并执行之,执行完成后,父进程继续等待从终端读入命令。熟悉DOS和WINDOWS系统调用的朋友一定知道DOS/WINDOWS也有exec类函数,其使用方法是类似的,但DOS/WINDOWS还有spawn类函数,因为DOS是单任务的系统,它只能将“父进程”驻留在机器内再执行“子进程”,这就是spawn类的函数。 WIN32已经是多任务的系统了,但还保留了spawn类函数,WIN32中实现spawn函数的方法同前述UNIX中的方法差不多,开设子进程后父进程等待子进程结束后才继续运行。UNIX在其一开始就是多任务的系统,所以从核 心角度上讲不需要spawn类函数。
另外,有一个更简单的执行其它程序的函数system,它是一个较高层的函数,实际上相当于在SHELL环境 下执行一条命令,而exec类函数则是低层的系统调用。
(四) Linux的进程与Win32的进程/线程有何区别
熟悉WIN32编程的人一定知道,WIN32的进程管理方式与UNIX上有着很大区别,在UNIX里,只有进程的概念 ,但在WIN32里却还有一个“线程”的概念,那么UNIX和WIN32在这里究竟有着什么区别呢?
UNIX里的fork是七十年代UNIX早期的开发者经过长期在理论和实践上的艰苦探索后取得的成果,一方面, 它使操作系统在进程管理上付出了最小的代价,另一方面,又为程序员提供了一个简洁明了的多进程方法。
WIN32里的进程/线程是继承自OS/2的。在WIN32里,“进程”是指一个程序,而“线程”是一个“进程” 里的一个执行“线索”。从核心上讲,WIN32的多进程与UNIX并无多大的区别,在WIN32里的线程才相当于UNIX 的进程,是一个实际正在执行的代码。但是,WIN32里同一个进程里各个线程之间是共享数据段的。这才是与 UNIX的进程的不同。
下面这段程序显示了WIN32下一个进程如何启动一个线程:(请注意,这是个终端方式程序,没有图形界面 )
int g;
DWORD WINAPI ChildProcess( LPVOID lpParameter ){
int i;
for ( i = 1; i < 1000; i ) {
g ;
printf( "This is Child Thread: %d\n", g );
}
ExitThread( 0 );
};
void main()
{
int threadID;
int i;
g = 0;
CreateThread( NULL, 0, ChildProcess, NULL, 0, &threadID );
for ( i = 1; i < 1000; i ) {
g ;
printf( "This is Parent Thread: %d\n", g );
}
}
在WIN32下,使用CreateThread函数创建线程,与UNIX不同,线程不是从创建处开始运行的,而是由 CreateThread指定一个函数,线程就从那个函数处开始运行。此程序同前面的UNIX程序一样,由两个线程各打印1000条信息。threadID是子线程的线程号,另外,全局变量g是子线程与父线程共享的,这就是与UNIX的不同之处。大家可以看出,WIN32的进程/线程要比UNIX复杂,在UNIX里要实现类似WIN32的线程并不难,只要fork以后,让子进程调用ThreadProc函数,并且为全局变量开设共享数据区就行了,但在WIN32下就无法实现类似fork的功能了。所以现在WIN32下的C语言编译器所提供的库函数虽然已经能兼容大多数UNIX的库函数, 但却仍无法实现fork。
对于多任务系统,共享数据区是必要的,但也是一个容易引起混乱的问题,在WIN32下,一个程序员很容易忘记线程之间的数据是共享的这一情况,一个线程修改过一个变量后,另一个线程却又修改了它,结果引起程序出问题。但在UNIX下,由于变量本来并不共享,而由程序员来显式地指定要共享的数据,使程序变得 更清晰与安全。
Linux还有自己的一个函数叫clone,这个函数是其它UNIX所没有的,而且通常的Linux也并不提供此函数(要使用此函数需自己重新编译内核,并设置CLONE_ACTUALLY_WORKS_OK选项),clone函数提供了更多的创建新进程的功能,包括象完全共享数据段这样的功能。
至于WIN32的“进程”概念,其含义则是“应用程序”,也就是相当于UNIX下的exec了。
Linux需要重新启动是少有的。可是一旦需要,Linux启动常常是缓慢的。幸好有一些加速的办法。其中一些方法不太难。咱们瞧一瞧吧。
1: 撤消多余的服务
根据机器的用途,很多服务是不需要的。要是Linux只用作桌面,就不需要sendmail、httpd和另外许多服务。如果你的服务器只是Web服务器,也可以关掉许多服务。为此,可转到管理菜单,检查服务项目。只需撤消所有不想启动的服务选项。
2: 撤消多余的内核模块
假如你的桌面连接到以太网,就不需要装载无线内核模块。这是较为困难的任务,可能需要重新编译内核,而编译内核不是可以轻松担当的工作。为此,你大概需要内核源代码。接着,按照编译内核的标准步骤进行。不同在于你要搜查系统,撤除所有不需要的模块。
查明系统中当前安装和运行的内核模块的方法是安装Bootchart。它不仅会给你一个适宜的模块清单,而且还会说明系统启动过程中发生的事情。还可以发出命令:chkconfig –list | grep 3:on,弄清楚正在运行什么服务。一旦知道装载了什么不需要的模块,就可以在内核重新编译期间将其移除。只要这样处理,编译的内核就完全适合你的体系结构。
3: 使用轻型窗口管理器代替GNOME或KDE
我插入小脚印窗口管理器的原因是——它们大幅度减少图形(界面)启动时间。代替不得不额外等待启动GNOME或KDE的30到60秒,为什么不等待用于启动Enlightenment或者XFCE的2到10秒呢?它们不仅节省启动时间,还会节省内存并解救处理臃肿软体(bloatware)这种令人头痛的事。
4: 使用基于文本的登录而不是图形登录
我的大多数Linux机器启动run level 3而非run level 5。这个运行级别将停在文本登录模式,我就在这个地方登录并发出startx命令,开始选择桌面。图形登录模式做两件事:增加装入时间并引起头痛的问题即试图从拙劣的X windows挣脱出来。
5: 使用轻型发行版
不要装载重型的Fedora,为什么不试一下Gentoo、Arch或Puppy Linux呢?这些较小的发行版的启动时间比更加臃肿的Fedora(甚至Ubuntu)要快很多。在较大的发行版中,OpenSuSE声称启动最快,但我还没有亲自试验。在的Fedora和Ubuntu之间,Ubuntu击败Fedora的启动时间(而且是即开即用)。
6: 使用Open BIOS
要是你相当聪明能干,准备升级PC固件,可以考虑迁移到开源BIOS。一个附加说明,使用开放固件允许Linux启动时真正初始化硬件(而不依赖BIOS)。最重要的是,许多开放BIOS可以设置满足机器的特殊需要。如果不走开放BIOS之路,至少也可以设置BIOS不寻找不存在的软盘驱动器,即直接启动个硬盘驱动器(首先不是CD驱动器)。
7: 回避DHCP
如果你工作在地址租约不是问题的家庭网络(或者小型企业网络)上,那么,机器就用静态IP地址。这将使机器不必出外访问DHCP服务器来获得IP地址。如果采取这种途径,就要确保配置文件/etc/resolve.conf也表达你的DNS服务器地址。 8: 热插拔可免就免
热插拔是指允许把新设备插上电源并立即使用的系统。如果你知道你的服务器不需要这种系统,就删除它。这将减少启动时间。在许多系统上,热插拔消耗大量启动时间。排除热插拔将发生的变化取决于你所用的发行版。注意:就绝大部分而言,udev已经取代热插拔。但如果你还在运行老一点的发行版,这样做还是适合的。
9: 要是真的大胆无畏,可尝试一下initng
initng系统充当sysvinit系统的替换物,并承诺彻底减少类UNIX操作系统的启动时间。如果你愿意了解运行中的initng系统,可以试一试Pingwinek LiveCD。
10: 利用Debian具有的代码
要是正在使用Debian,就有一行可用来将你的启动脚本转换成并行运行的简单代码。如果检查一下/etc/init.d/rc脚本,就会看到:大约在24行有CONCURRENCY=none。把这一行改为CONCURRENCY=shell,你有可能目睹启动时间的减少。
上述大部分应该是最重要的,当然最快的使Linux启动提速的方法就是不要重启,所以,极少重新启动一般可以减轻启动时间的担子。
维库电子通,电子知识,一查百通!
已收录词条308934个


